Scaling services with Karpenter, HPAs and Kubernetes Requests (Even through Hurricane Melissa)
That title is just Cloud word salad man..
The set up is worth it, bear with me
Ok, I know what you're probably thinking, "Jordan, look at that title man, look at all the words you put together, just increase the RAM and CPU and call it a day" but trust me, this setup will be worth it. Scaling is an ever elusive and daunting topic in Computer Science. When to scale? Where to scale? How to scale? Can all be answered by our favourite age old answer:

In this instance though, I'll be speaking to auto scaling within the context of EC2s, Kubernetes and Karpenter. In simple terms, increasing more compute and memory when we need it automatically.
TLDR: Just Use Karpenter with Horizontal Pod Autoscalers and CPU/Memory requests
For the impatient and well informed, what I describe in this article is relatively simple. Start by configuring Karpenter in your cluster with helm or via <Insert_your_flavour_of_IAC_tool_here>. Once you have that configured, simply add a HPA to your application, set the resource requests, but not the limits, see For the Love of God, Stop Using CPU Limits on Kubernetes
If you're a visual learner (like me), it can be explained with this diagram.
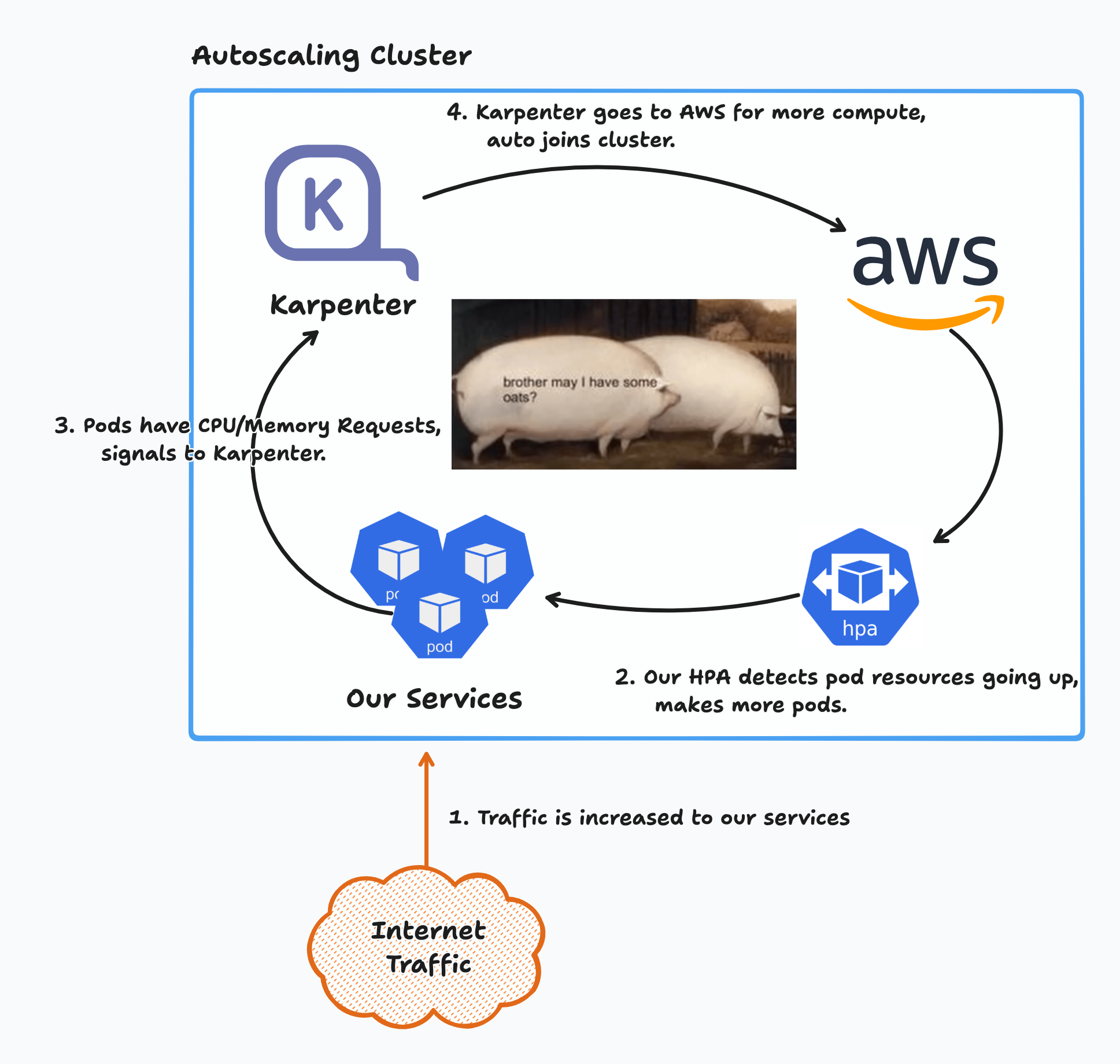
In summary, what happens here is that resource requests are set on pods and the hpa will make more pods once the utilization threshold is reached (cpu/memory), the scheduler will try to find a suitable node for the incoming pods, if it can't, Karpenter will grab a new node (EC2) from AWS and add it to the cluster.
This is a rather basic setup but it got the job done for what I needed, which in this case was managing the traffic spikes during Hurricane Melissa.
If you'd like to see how this could be set up, keep reading!
How Karpenter Scales
Around a year ago, AWS released v1.0.0 of one my favourite tools, Karpenter, which it's tag line describes itself as "Just In Time Nodes for Any Kubernetes Cluster". What a great description; Karpenter gives K8s clusters native auto scaling capabilities once configured properly.
Again, simply put, it gives you more resources (nodes) when your pods/processes request it.
It kicks off when the pods come under pressure, more than likely from increased traffic thus, requiring more cpu and more memory.
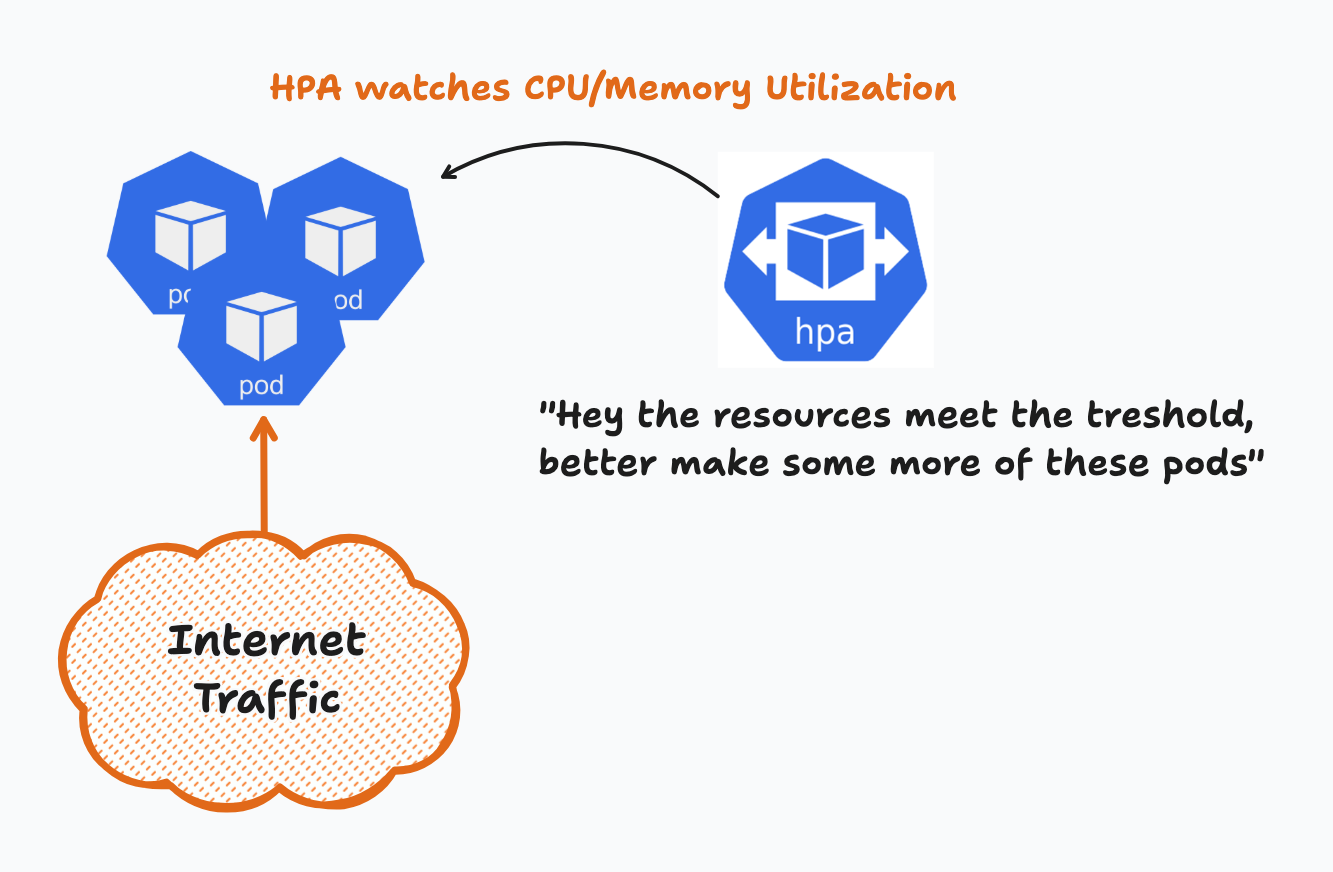
A basic HPA might look something like this
# hpa.yaml
type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
and the resource requests in our k8s pod might look like:
# pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
# Pay attention to here
requests:
memory: "1000Mb"
cpu: "1"
Because the requests are set on the pods, once the HPA scales the pods, the cluster will acknowledge and try to fill those requests on a node with available capacity.

Now you might be thinking "Ok, so what if it can't find a suitable Node?", that's where Karpenter comes in.
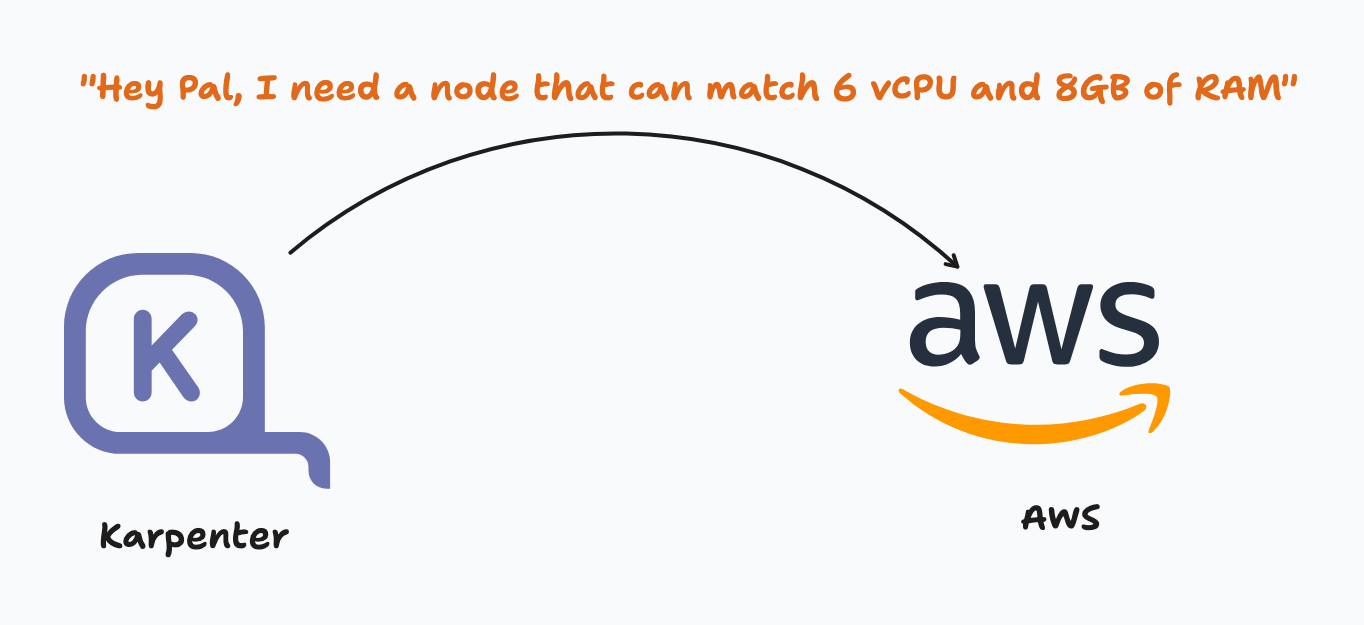
Karpenter (via the pod) will make a NodeClaim, based on a configured NodePool, which is a fancy way to say "It's gonna find a suitable EC2 node from a predefined list of EC2 Instance Classes (that you define)."
Once a suitable EC2 class is found, Karpenter will set this node up and have it join the cluster. Voila, your newly replicated pods can now be scheduled and you now can manage a greater scale of traffic.
If you're using OpenTofu or Terraform, there's an eks karpenter module available https://registry.terraform.io/modules/terraform-aws-modules/eks/aws/latest/submodules/karpenter to set this up in your cluster.
Alternatively, you can install it via the karpenter helm chart
Conclusion
So, assuming we correctly set our cluster up and installed karpenter with our NodePool and NodeClaim, now we have a cluster that autoscales under load!
Naturally this isnt an exhaustive description of all the moving parts but merely a high level overview of how I managed to serve workloads quickly during Hurricane Melissa.